Our goal is to understand molecular mechanisms that mediate the multiple reactions required for the replication of a chromosome. We use structure studies of the proteins, their functional sub-assemblies, and the replisome itself, combined with genetic and biochemical analyses of the reactions they mediate. An essential component is to define the protein-protein interactions that coordinate the individual steps of replication.
Background
 In recent years considerable progress
has been made in understanding the
reactions catalyzed by the proteins of
DNA replication. However, many
questions remain concerning the function of individual proteins, aside fromthe more complex processes of initition of replication at chromosomal origins and the coordination of events at a replication fork. Even in the case of DNA polymerases, where the wealth of enzymatic data gathered over the years can now be interpreted in light of the three dimensional structures of the proteins, questions pertaining to the basis of nucleotide selection and the coordination of proofreading with polymerization remain. Likewise the mechanism of unidirectional movement of the DNA helicase on a DNA strand and the unwinding of the duplex are unsolved. Less well characterized are the DNA primases, an intriguing class of enzymes whose zinc motif plays an essential role in sequence recognition. Even single-stranded DNA binding proteins, often relegated to mundane roles, are emerging as key components in coordinating reactions at origins and replication forks. More complex are the interactions of the helicase and primase with one another and their interaction, in turn, with the polymerase where helicase and polymerase movement must be coordinated and primers transferred to the polymerase. Least well understood are the coordination of leading and lagging strand synthesis and the recycling of the polymerase from one Okazaki fragment to a new primer.
In recent years considerable progress
has been made in understanding the
reactions catalyzed by the proteins of
DNA replication. However, many
questions remain concerning the function of individual proteins, aside fromthe more complex processes of initition of replication at chromosomal origins and the coordination of events at a replication fork. Even in the case of DNA polymerases, where the wealth of enzymatic data gathered over the years can now be interpreted in light of the three dimensional structures of the proteins, questions pertaining to the basis of nucleotide selection and the coordination of proofreading with polymerization remain. Likewise the mechanism of unidirectional movement of the DNA helicase on a DNA strand and the unwinding of the duplex are unsolved. Less well characterized are the DNA primases, an intriguing class of enzymes whose zinc motif plays an essential role in sequence recognition. Even single-stranded DNA binding proteins, often relegated to mundane roles, are emerging as key components in coordinating reactions at origins and replication forks. More complex are the interactions of the helicase and primase with one another and their interaction, in turn, with the polymerase where helicase and polymerase movement must be coordinated and primers transferred to the polymerase. Least well understood are the coordination of leading and lagging strand synthesis and the recycling of the polymerase from one Okazaki fragment to a new primer.
The Bacteriophage T7 Replication System
In order to address these questions of DNA replication our laboratory has focused on the replication system derived from Escherichia coli infected with bacteriophage T7. The T7 chromosome is replicated in a fashion characteristic of more complex bacterial and eukaryotic systems. Initiation of replication occurs at a primary origin, replication is bi-directional, and lagging strand DNA synthesis is dependent on multiple initiation events. Consequently, T7 DNA replication requires a processivity factor (E. coli thioredoxin) for the DNA polymerase (T7 gene 5 protein), a helicase-primase (T7 gene 4 protein), a single-stranded DNA binding protein (T7 gene 2.5 protein), and other accessory proteins such as a 5' to 3' exonuclease (T7 gene 6 exonuclease) and a DNA ligase (T7 gene 1.3 protein). T7 has evolved an efficient and economical mechanism for the replication of its DNA, one that probably defines the minimal requirements for the rapid and faithful replication of a duplex DNA molecule. The limited number of proteins involved in T7 replication offers two major advantages: (i) the stoichiometry of the proteins in functional complexes is facilitated by the limited number of permutations, and (ii) a determination of the three dimensional structure of functional complexes is an achievable goal which we are pursuing in collaboration with the laboratory of Tom Ellenberger .
Several examples illustrate the simplicity of functional complexes in the T7 replication system. Thioredoxin, the processivity factor, binds to the polymerase to clamp the complex onto a primer-template. Economy dictates that the polymerase provide one-half the clamp; assembly occurs without accessory proteins, in contrast to the situation in E. coli and phage T4 . Similarly, the T7 gene 4 protein provides both helicase and primase activities at the replication fork whereas in other systems these activities are provided by separate proteins. The experimental utility of a limited number of proteins is most apparent in studies on the T7 replisome. We have constructed a T7 replisome, consisting of only four proteins, that fulfills all of the predictions that arise from models of coupled leading and lagging strand synthesis.
Current Research projects
Initiation of DNA replication
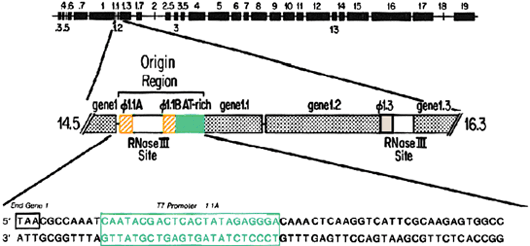
Studies on initiation of DNA replication focus on the role of each of several elements located in the primary origin of replication. The primary origin is located 15% of the distance from the genetic left end of the T7 chromosome and it consists of two T7 RNA promoters followed by an AT-rich region. Initiation requires transcriptional activation by T7 RNA polymerase, the product of gene 1. Dissection of the initiation process involves Site-specific mutagenesis of the cloned origin combined with reconstitution of the proteins.
Acquisition of host functions
Although T7 encodes most of its replication proteins it does make use of several host proteins and modifies others. The T7 gene 1.2 protein is an inhibitor of E. coli dGTPase, gene 2 protein inhibits E. coli RNA polymerase, gene 1.7 protein is involved in nucleotide precursor synthesis, and the gene 0.7 protein kinase affects the activity of several host proteins.
T7 DNA polymerase
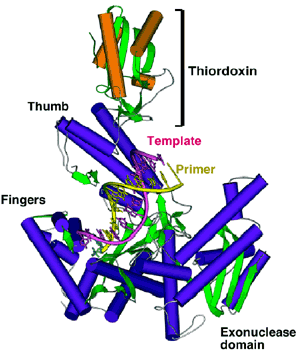 The crystal structure of T7 DNA polymerase complexed
to a primer-template, a deoxynucleoside triphosphate, and
its processivity factor provides insight into polymerization
and suggests future studies. Differences in the structures of
T7 DNA polymerases relative to other members
of this family provide one approach to identifying
domains that interact with other T7 replication proteins.
This approach has identified a single residue responsible
for the ability of T7 DNA polymerase to distinguish
between a deoxyribose and dideoxyribose. Likewise,
a unique 71 amino acid insert found in the thumb of
T7 DNA polymerase provides the binding site for
thioredoxin, the processivity factor, and a small loop
in the DNA binding crevice interacts with the
T7 DNA primase/primer complex.
The crystal structure of T7 DNA polymerase complexed
to a primer-template, a deoxynucleoside triphosphate, and
its processivity factor provides insight into polymerization
and suggests future studies. Differences in the structures of
T7 DNA polymerases relative to other members
of this family provide one approach to identifying
domains that interact with other T7 replication proteins.
This approach has identified a single residue responsible
for the ability of T7 DNA polymerase to distinguish
between a deoxyribose and dideoxyribose. Likewise,
a unique 71 amino acid insert found in the thumb of
T7 DNA polymerase provides the binding site for
thioredoxin, the processivity factor, and a small loop
in the DNA binding crevice interacts with the
T7 DNA primase/primer complex.
gene 4 helicase-primase
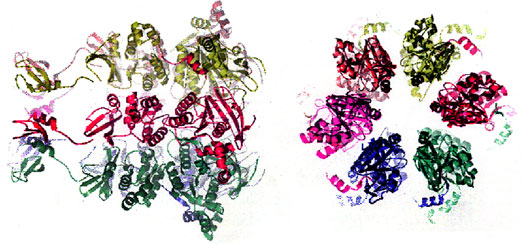
The multifunctional gene 4 protein provides helicase and primase activities at the replication fork. The C-terminal half of the protein contains the helicase domain and the N-terminal half the primase domain. Each domain has been cloned and thus the two activities can be studied independently.
The hexameric helicase domain is structurally homologous to the F1-ATPase of the molecular motor protein super-family. The crystal structure of the helicase domain suggests a number of biochemical and genetic approaches to identifying the steps involved in coupling DNA unwinding to the conformational changes arising from the binding and hydrolysis of dTTP.
T7 DNA primase recognizes a trinucleotide sequence at which it synthesizes a tetraribonucleotide. The primase domain has been crystallized and shown to contain sub-domains found in topoisomerases, RNA polymerases, and transcription factors. A Cys4 zinc motif plays an important role in sequence recognition. In vitro mutagenesis has led to identification the NTP binding sites, the residues involved in phosphodiester formation, and those responsible for sequence recognition.
Single-stranded DNA binding protein
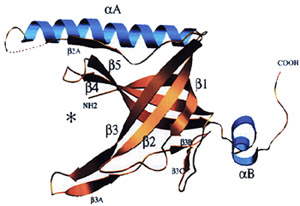 The T7 gene 2.5 single-strand binding protein interacts with all the T7 replication proteins and is essential for coordination of reactions at a replication fork. Although the gene 2.5 protein has no sequence homology with other DNA binding proteins it does have extensive structural homology. The gene 2.5 protein dimer not only binds to single-stranded DNA but it also mediates homologous base-pairing.
The T7 gene 2.5 single-strand binding protein interacts with all the T7 replication proteins and is essential for coordination of reactions at a replication fork. Although the gene 2.5 protein has no sequence homology with other DNA binding proteins it does have extensive structural homology. The gene 2.5 protein dimer not only binds to single-stranded DNA but it also mediates homologous base-pairing.
Coordination of reactions at a replication fork
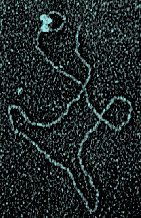 A mini-circle replication system in which leading and lagging strand synthesis are coupled and the lagging strand polymerase operates processively
has been used to dissect protein interactions at the replication fork. In collaboration with the laboratory of Jack Griffith at the University of North Carolina-Chapel Hill we find that the majority of the replicating molecules have a replication loop consisting of single and double-stranded segments of DNA whose lengths determine the size of the observed Okazaki fragments. Unresolved questions concern the mechanism of formation of the replication loop, the frequency of use of primase recognition sites, and the mechanism of processivity of the lagging strand DNA polymerase.
A mini-circle replication system in which leading and lagging strand synthesis are coupled and the lagging strand polymerase operates processively
has been used to dissect protein interactions at the replication fork. In collaboration with the laboratory of Jack Griffith at the University of North Carolina-Chapel Hill we find that the majority of the replicating molecules have a replication loop consisting of single and double-stranded segments of DNA whose lengths determine the size of the observed Okazaki fragments. Unresolved questions concern the mechanism of formation of the replication loop, the frequency of use of primase recognition sites, and the mechanism of processivity of the lagging strand DNA polymerase.
Replication proteins from other replication systems
Several projects involve replication proteins from other replication systems. The molecular detail available from the phage T7 studies frequently provides insight into approaches to proteins from other viruses and organisms. In addition the detection of differences between two similar proteins provides an approach to determining the structural basis for these differences. Studies involve E. coli DNA polymerase I, bacteriophage T5 DNA polymerase, the SP6 DNA primase, and HIV-1 reverse transcriptase.
Replication proteins as reagents in molecular biology and genomics

Not surprisingly, proteins of DNA metabolism are themselves useful as reagents for nucleic acid studies. Several of the proteins discovered or modified in our laboratory fall within this category. E. coli exonuclease III and phage T7 gene 6 exonuclease are useful for constructing duplex DNA molecules having single-stranded overhangs. E. coli exonuclease VII, hydrolyzing single-stranded DNA from 3' and 5' termini has found utility in removing such termini from duplex DNA molecules and in assays on RNA splicing. Polynucleotide kinase encoded by phage T4 enables the radioactive labeling of the 5'-termini of both RNA and DNA. Phage T4 DNA ligase is an essential component of recombinant DNA technology. The T7 DNA polymerase/thioredoxin complex, chemically or genetically modified, offers many advantages for DNA sequence analysis. Thermostable enzymes such as the Thermus aquaticus DNA polymerase can be modified to incorporate chain terminating dideoxynucleotides, making them useful in automated DNA sequencing.